Generative policies have emerged as a promising paradigm for robot learning, combining expressive generative
action modeling with scalable imitation learning from large demonstration corpora. Yet when trained on
heterogeneous demonstrations, their chunked generation process can produce suboptimal actions, causing errors
to compound during execution and eventually driving the robot into out-of-distribution failure states.
Action verification has recently emerged as a test-time scaling approach to mitigate this issue — sampling
multiple action candidates and using an external verifier to select the best one. However, existing approaches
remain temporally myopic: they evaluate candidates using only static-timestep observations,
and often rely on large-scale verifiers and additional expert demonstrations.
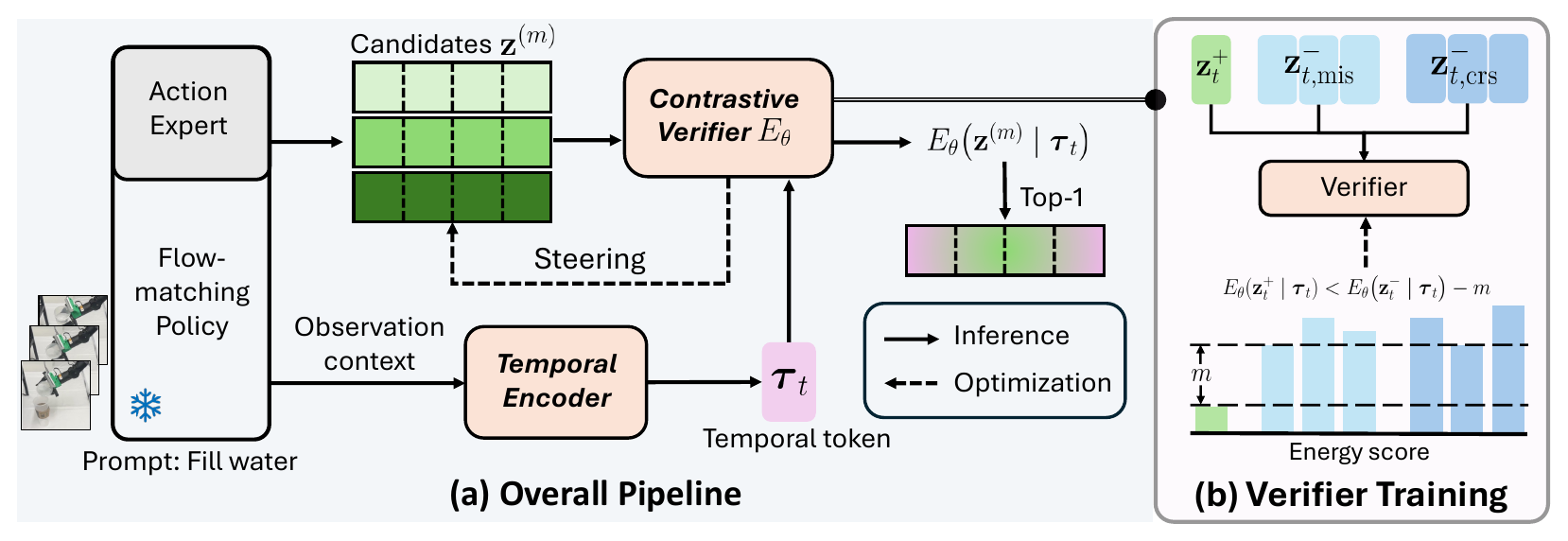
We introduce Temporal Verification (TeV), an efficient temporally aware action verification
framework for flow-matching VLAs. TeV first learns a temporal token that summarizes recent
observation–action history, allowing candidate chunks to be evaluated as continuations of the robot's
execution trajectory rather than isolated predictions. Conditioned on this token, TeV constructs
positive–negative sample pairs without additional expert data or preference annotations, and trains an
energy-based verifier with a contrastive objective to favor higher-quality chunks that are
temporally compatible with recent execution.
Beyond post-hoc ranking, TeV uses the learned energy score to steer intermediate samples
toward lower-energy regions during flow integration. The verifier adds less than 0.15% parameters on top of
the frozen base policy and requires no additional expert demonstrations. Extensive experiments in simulation
and real-world settings show that TeV provides reliable action candidate ranking, yields consistent
task-success gains of 6%–18%, and produces smoother execution trajectories.