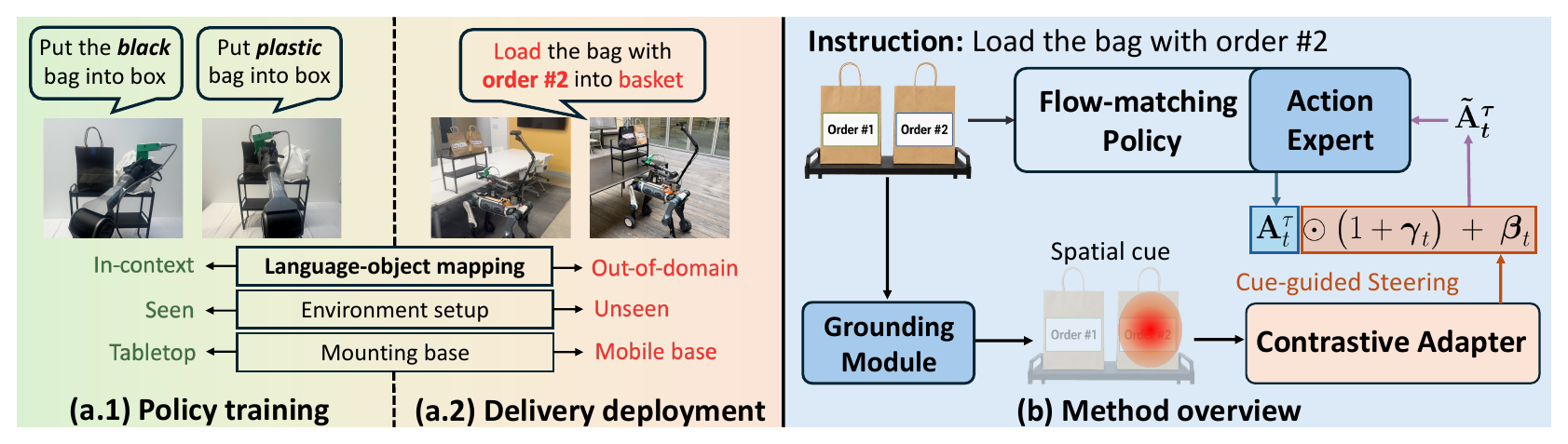
Open-world delivery requires mobile manipulators to follow free-form user instructions and manipulate
potentially novel objects. Existing dual-system approaches use high-level grounding models to convert
language into grounded visual prompts, but their low-level controllers can remain brittle under noisy
perception, dynamic scenes, and contact-rich interactions.
We instead use a pretrained flow-matching vision-language-action model as the low-level control
interface, leveraging its reactivity and robustness to environmental changes while treating the
grounding output as a spatial cue for policy steering. Our key insight is that the pretrained
VLA already provides a strong manipulation prior, while the spatial cue supplies the missing target
information needed to guide actions under novel language–object mappings.
Concretely, we introduce a lightweight cue-conditioned adapter. The adapter is first trained
with contrastive objectives to produce salient and spatially discriminative cue representations, and is then
supervised to predict a diagonal affine transformation over the generated action chunk, aligning policy
steering with the cued target. Across tabletop and mobile-base settings, our method improves instruction
following and manipulation success on both in-domain and out-of-domain objects, achieving up to
near 2× improvement in average task success rate with negligible inference overhead.